- Firefox-Version
- 121.0.1
- Betriebssystem
- Windows 10
Hallo,
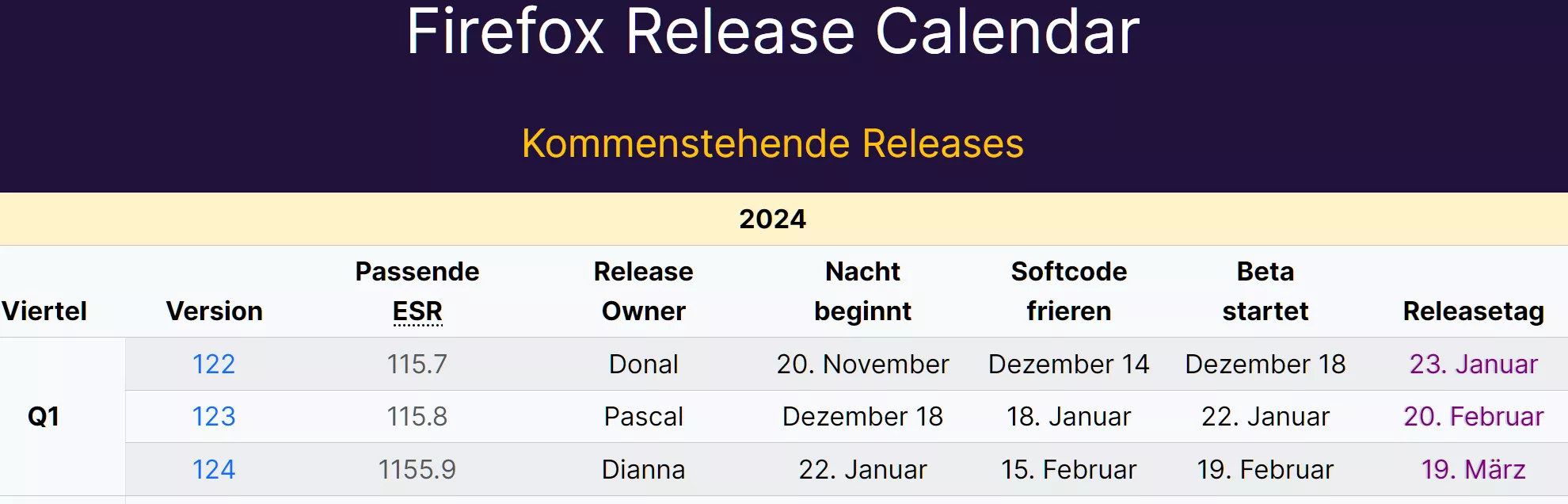
seit einiger Zeit habe ich das Problem, dass mir Firefox Seiteninhalte derart verändert, dass Worte völlig unsinnig ausgetauscht werden (siehe Beispiele).
Ich habe natürlich bereits Cache und Cockies gelöscht, alle Add-Ons deaktiviert usw. Nützt alles nichts.
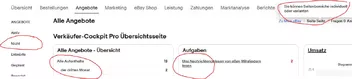
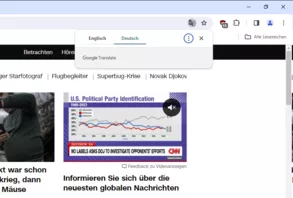
Das erste Bild zeigt den gewünschten Inhalt korrekt aus MS Edge, das zweite den verhunzten Text aus Firefox.
Oft sieht man in Firefox nur ganz kurz für 0,5-1 sec. den richtigen Text, dann sofort den verhunzten Text.
Wer weiß Rat?
Gruß
Martin